
Introduction
Most manufacturing facilities don't lose production to sudden, unpredictable failures. They lose it to failures they almost saw coming — the bearing that had been running rough for weeks, the pump temperature that crept up month by month, the fault trip that happened three times before the big shutdown.
Unplanned downtime costs the world's 500 largest industrial companies approximately $1.4 trillion annually, equal to 11% of revenues, according to Siemens' 2024 True Cost of Downtime report. For a large automotive plant, that averages $695 million per year in losses. For FMCG manufacturers, around $10 million.
The shift from reactive firefighting to AI-driven prevention is no longer a future-state aspiration. It's a current competitive divide — and the gap between facilities that have made it and those still running calendar-based maintenance schedules is widening every year.
This article breaks down what you need to act on that gap:
- Why equipment failures happen — and why most are preventable
- What early warning signs look like across common failure modes
- How AI predictive maintenance maps to each root cause
- Where to start if your facility is still on calendar-based schedules
Key Takeaways
- Unplanned equipment failures almost always have detectable precursors — mechanical wear, data blind spots, and undocumented knowledge gaps rank among the most common root causes.
- $695 million per year is what a large automotive plant loses on average to downtime; even FMCG facilities average over $10 million annually.
- AI predictive maintenance converts gradual sensor deviations into specific, actionable failure warnings — days or weeks before breakdowns.
- With 54,200 maintenance technician openings projected per year through 2034, capturing expert knowledge before it walks out the door is now a maintenance priority.
- Connecting AI alerts directly to work orders closes the gap between prediction and action — the step that turns data collection into actual downtime reduction.
Common Causes of Unplanned Equipment Failures
Equipment failures rarely materialize without warning. They build from identifiable root causes that go undetected until the damage is done.
Mechanical Wear and Physical Degradation
Bearing wear, shaft misalignment, rotating component imbalance, and lubrication breakdown are the most common physical failure triggers in manufacturing. None of them happen suddenly — each degrades performance over weeks or months before reaching a failure threshold.
According to Plant Engineering's 2021 maintenance study, aging equipment was the leading cause of unscheduled downtime, ahead of mechanical failure, operator error, and training gaps. As industrial assets age, degradation rates accelerate and calendar-based maintenance schedules become increasingly poor predictors of actual equipment condition.
Reactive and Over-Scheduled Maintenance Practices
Two dysfunctional patterns dominate factory floors, often simultaneously:
- Run-to-failure — waiting for breakdown before acting. Catastrophic damage is the typical result, with cascading impact on connected equipment.
- Fixed-interval preventive maintenance — replacing parts on a schedule regardless of actual condition. This wastes resources and can introduce new failure modes from unnecessary part swaps.
NIST's manufacturing machinery maintenance analysis found that facilities most reliant on reactive maintenance had 3.3 times more downtime and 16 times more defects than those least reliant on it. Yet the same research shows the average facility's maintenance strategy mix is still 45.7% reactive — with predictive maintenance accounting for just 17.3%.

That gap matters. Most facilities report preventive maintenance as their primary strategy, but their actual maintenance mix says otherwise.
Loss of Operator Tribal Knowledge
When an experienced technician retires, undocumented knowledge leaves with them. Examples that never make it into any system:
- The sound a bearing makes two weeks before it fails
- The fault code sequence that reliably precedes a shutdown
- The informal workaround that keeps a specific press running between services
The scale of this problem is accelerating. The BLS projects 54,200 maintenance technician openings per year through 2034 — with many driven by retirement. Deloitte and the Manufacturing Institute project U.S. manufacturing may need 3.8 million net new employees by 2033, with roughly 1.9 million jobs potentially unfilled if skills gaps persist.
This isn't just an HR problem. It's a maintenance reliability problem. Every retirement without knowledge capture is a degraded ability to catch early warning signs.
Sensor Blind Spots and Disconnected Data
Many facilities have sensors. Few have the full picture. PLCs, historians, and CMMS systems collect equipment data in isolated silos that rarely communicate — meaning an anomaly that would be obvious in a connected view goes undetected because no single system sees it.
Even facilities with decent sensor coverage often lack the analytics layer to convert raw readings into actionable warnings. Data collected is not the same as data used. Without pattern recognition across multiple signals, a bearing failure visible in three combined readings goes undiagnosed until it trips an alarm.
What Happens When Equipment Failures Go Unchecked
The direct repair cost is rarely the most expensive part of an unplanned failure. The full cost compounds:
- Lost production during the unplanned stop
- Emergency labor premiums for unscheduled repair crews
- Expedited parts procurement at above-standard cost
- Cascading damage to connected equipment that was still running during the degraded state
- Safety and quality incidents — equipment operating in degraded condition increases defect rates and the likelihood of regulatory non-compliance
Siemens' 2024 report puts the average large plant downtime loss at $253 million per year across surveyed industrial sectors. Automotive plants average $2.3 million per hour of downtime.
These numbers make the case for catching problems early. AI predictive maintenance systems are specifically designed to detect these indicators before they become failures:
Warning Signs You're Approaching a Failure Event
- Abnormal or increasing vibration readings — often the earliest mechanical signal
- Temperature trending above normal operating range — gradual creep is frequently missed on manual inspection rounds
- Rising electrical current draw at the same load — signals mechanical resistance increasing
- Increased fault trip frequency — repeated minor trips before a major failure is a reliable pattern
- Unexpected changes in cycle times or output quality — downstream indicators of upstream degradation

Sensors don't catch everything first. Operators often notice behavioral changes before any instrument registers an anomaly — a different sound, a subtle vibration felt through the floor, a machine that "just feels off." Most predictive maintenance programs have no structured way to capture and act on those observations. That gap is where failures slip through.
How AI Predictive Maintenance Prevents Equipment Failures
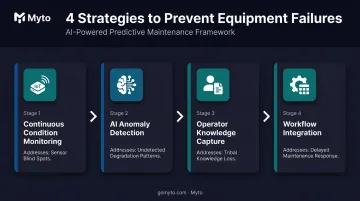
Four complementary strategies work together to prevent failures: continuous condition monitoring, AI-powered anomaly detection, operator knowledge capture, and workflow integration. Each addresses a different root cause from the section above.
Continuous Condition Monitoring with IoT Sensors
What to do: Deploy vibration, temperature, current, and pressure sensors on critical assets to establish a real-time health baseline.
How it prevents failures: Fixed-schedule inspections create coverage gaps between visits. Continuous monitoring catches gradual deviations like temperature creep and increasing vibration amplitude that would be invisible to weekly or monthly manual rounds.
When to implement: Start with highest-impact assets (main production lines, critical pumps, presses) and use non-invasive sensor mounting to avoid downtime during deployment. Most legacy equipment can be instrumented without modification.
AI and Machine Learning Anomaly Detection
What to do: Feed sensor data into ML models trained on historical equipment performance. The model establishes what "normal" looks like for each asset and flags deviations that match known failure precursors.
How it prevents failures: GE Vernova's predictive analytics platform describes AI/ML digital twins detecting minor anomalies days, weeks, or months before traditional alarms would trigger — translating sensor drift into specific warnings with estimated failure timelines. Peer-reviewed case studies on industrial equipment report ML model accuracy rates above 98% in controlled conditions, though real-world performance varies by asset type, data quality, and model maturity.
McKinsey's 2021 analysis adds an important caveat: a 10% false-positive rate can wipe out projected savings. Model accuracy and alert calibration aren't optional : they determine whether teams trust the system or start ignoring its warnings.
When to implement: Start with threshold-based alerts on simple patterns, then layer in ML models as historical data accumulates. Prioritize assets where downtime cost justifies the investment.
Capturing and Systematizing Operator Knowledge
What to do: Build a structured process to capture the diagnostic knowledge your best technicians carry : how equipment sounds before failure, which fault codes reliably precede shutdowns, what workarounds keep lines running. Convert that into documented workflows accessible to the entire team.
How it prevents failures: When frontline expertise is systematized, less experienced workers can identify early warning signs that would otherwise require a veteran in the room. That knowledge compounds over time and survives workforce turnover.
According to MaintainX's 2025 State of Industrial Maintenance report, knowledge capture and sharing was the top-cited AI benefit at 39% , ahead of reducing unexpected equipment failure at 36%. That ranking reflects a real operational priority: teams understand that the AI models are only as good as the knowledge fed into them.
Myto's platform addresses a gap that sensor systems alone can't fill. Operators wear AI glasses that record troubleshooting steps, equipment maneuvers, and expert behavior while they work — no separate documentation step required.
That footage is automatically structured by agentic AI into SOPs, troubleshooting flows, fault-code correlation guides, and shift-handover documentation.
When a newer technician encounters spindle vibration, the system surfaces equipment history: last bearing replacement, expected lifespan, and prior failure modes. It loads the relevant SOP, identifies likely root causes (inadequate lubrication, coolant contamination, operating above rated speed), and walks them through a diagnostic checklist with visual aids. The senior tech's knowledge is in the workflow, not locked in their head.
Integrating Predictive Alerts into Maintenance Workflows
What to do: Connect AI failure predictions to existing CMMS or work order systems so that a flagged sensor anomaly automatically generates a maintenance ticket, suggests required parts, and proposes a scheduling window during planned downtime.
How it prevents failures: An alert only prevents a failure if it becomes a work order: assigned, scheduled, and completed before the failure threshold is crossed.
Myto's agentic AI agents are designed to do exactly this: opening tickets when a machine acts up, drafting shift-handover notes, scheduling maintenance follow-ups, and surfacing context to the next operator who touches that asset. The system sits on top of existing CMMS platforms (Maximo, Fiix, UpKeep, eMaint, Limble) without replacing them.
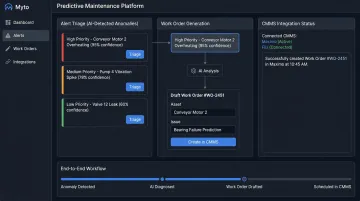
When to implement: Build the CMMS connection during the pilot phase. Define clear ownership for alert triage from day one. Prediction fatigue (where teams stop responding because alerts are too frequent or too inaccurate) kills programs faster than bad sensor data.
Tips for Long-Term Failure Prevention
Deploying sensors and AI models is the starting point, not the destination. Sustaining a predictive maintenance program requires operational discipline alongside the technology.
Keep Your Data Clean
Sensors drift, connectors corrode, and mounting positions shift. Routine calibration checks prevent false predictions that erode team trust — and a team that stops trusting alerts is back to reactive maintenance, with an expensive sensor infrastructure it ignores.
Make Knowledge Capture Continuous
Machines age, operating conditions change, and new failure modes emerge. The troubleshooting SOPs from three years ago may no longer match current practice.
Myto addresses this directly — capturing knowledge through AI glasses and agent workflows in the natural flow of work, so that operational intelligence compounds rather than goes stale. Each captured maintenance event and structured shift handoff makes the next technician's diagnosis faster.
Train Teams to Act on Alerts, Not Just Acknowledge Them
AI-generated warnings are only useful if the person receiving them knows what to do with an "elevated vibration — bearing health 67%" alert at 2 a.m. Effective training covers three things:
- Alert interpretation: what the reading means in practical terms
- Escalation ownership: who is responsible for each alert category
- Response habits: treating an alert as an urgent work order, not a notification to close
Conclusion
Unplanned equipment failures have identifiable causes — mechanical wear, reactive habits, knowledge gaps, and sensor blind spots — and each one is preventable with the right combination of technology and operational practice.
AI predictive maintenance is now within reach for mid-size and smaller manufacturing facilities, not just automotive giants or aerospace primes. Sensor costs have dropped, ML platforms have matured, and integration pathways to existing CMMS systems are well-established. For most facilities, the decision is no longer whether to adopt predictive maintenance — it's how quickly to scale it.
The gap between facilities operating on condition-based AI monitoring and those still running fixed-interval schedules will widen through 2026. Closing that gap means investing in sensors and AI models, but also in the knowledge layer underneath — capturing how experienced operators actually diagnose and resolve failures before that expertise leaves the floor. That's where platforms like Myto complement sensor-driven predictive systems, turning frontline expertise into structured, reusable intelligence that keeps production moving.
Frequently Asked Questions
What is the difference between predictive and preventive maintenance?
Preventive maintenance follows a fixed schedule regardless of actual equipment condition — you replace parts based on time or cycles, not machine health. Predictive maintenance uses real-time sensor data and AI to intervene only when equipment health signals indicate a developing problem, reducing both over-maintenance and unexpected failures.
What are the most common causes of equipment failure in manufacturing?
The leading causes are mechanical wear (bearing degradation, misalignment, lubrication failure), reactive maintenance practices, lost diagnostic knowledge as experienced operators retire, and sensor blind spots where early warning signals go unmonitored. Most failures involve more than one factor at once.
What data and sensors do I need to start AI predictive maintenance?
Vibration, temperature, current draw, and fault/alarm history are the highest-value starting signals. Most facilities can begin with non-invasive sensors on three to five critical assets before scaling — no major infrastructure changes required for initial deployment.
How long does it take to implement AI predictive maintenance?
A typical phased timeline: one to three months for assessment and pilot planning, four to six months for sensor deployment and model training on critical assets. Full-scale rollout with measurable ROI generally lands within 12 to 18 months.
What ROI can manufacturers expect from AI predictive maintenance?
McKinsey cites 18–25% maintenance cost reduction; Deloitte points to 10–50% downtime reduction and 10x–20x ROI potential. Both sources note that low-maturity implementations capture a fraction of those gains — calibration and false-positive control matter as much as the technology itself.
How does workforce aging affect equipment failure risk?
When experienced technicians retire, undocumented diagnostic knowledge goes with them, leaving teams less able to catch early warning signs. With the BLS projecting 54,200 maintenance technician openings per year through 2034, preserving that expertise has become a top use case for AI in manufacturing.


