
What makes unplanned downtime particularly difficult to address is that equipment failure is only part of the problem. Undocumented procedures, knowledge gaps, and poor shift communication are just as likely to keep a line down — yet they receive far less attention than preventive maintenance programs.
This guide covers the root causes of unplanned downtime, what it actually costs when left unaddressed, and a practical set of prevention strategies that work together to keep production moving.
Key Takeaways
- Unplanned downtime rarely has a single cause — equipment wear, human error, knowledge gaps, and external disruptions typically combine
- $400,000 per hour is the average cost for U.S. manufacturers, per a 2025 Fluke survey
- Knowledge gaps extend downtime far beyond the initial fault — when the right person isn't available, recovery stalls
- Prevention requires layered strategies — maintenance programs, standardized procedures, and knowledge systems reinforce each other
- Systems that learn from your operation compound in value over time; one-time fixes don't
Common Causes of Unplanned Downtime
Unplanned downtime is any unscheduled interruption to a machine, system, or process caused by an unexpected event — as distinct from planned downtime, which covers scheduled maintenance windows, changeovers, and upgrades that teams prepare for in advance.
The more important distinction: unplanned downtime rarely has a single cause. It typically results from multiple compounding issues that have been building undetected.
The four most common causes:
- Equipment wear and deferred maintenance — gradual degradation that accelerates when routine tasks get skipped
- Human error and inconsistent procedures — operator mistakes amplified by absent or outdated SOPs
- Tribal knowledge gaps — critical troubleshooting expertise that exists only in people's heads
- External disruptions — power failures and supply chain gaps that expose weak recovery plans

Equipment Wear and Deferred Maintenance
Friction, heat, vibration, and load stress gradually degrade every moving component. Skipping or delaying routine maintenance doesn't eliminate that wear — it accelerates it until failure becomes unavoidable.
A common scenario: a lubrication schedule slips during a busy production week. Six weeks later, during a peak shift, a bearing seizes. No spare part is on hand. What would have been a 30-minute scheduled task becomes an emergency shutdown lasting hours.
Human Error and Inconsistent Operating Procedures
Operator mistakes — incorrect machine settings, improper startup sequences, missed safety interlocks — are a leading cause of unplanned stoppages. The risk multiplies when SOPs are absent, outdated, or buried in a paper binder that nobody reads.
Shift handoffs are a particular vulnerability. A critical parameter adjustment goes uncommunicated between outgoing and incoming operators. The incoming team runs the line on the wrong settings. A quality fault shuts everything down mid-run.
Tribal Knowledge Gaps and Undocumented Processes
This is the most overlooked cause. The expertise needed to troubleshoot machines and keep lines running often lives exclusively in the heads of experienced operators. When those operators are absent, on another shift, or have left the company, that knowledge is gone.
The scale of this problem is significant. The Manufacturing Institute and Deloitte project that 2.8 million manufacturing job openings between 2024 and 2033 will result from retirements — each one representing accumulated expertise that could walk out the door permanently.
A typical scenario: a veteran technician knows the exact sequence to restart a finicky conveyor after a fault. They're on vacation. A newer operator has no documentation to reference, spends three hours troubleshooting, escalates to a supervisor — and the line sits idle the entire time.
Power Failures and External Disruptions
Not every downtime event originates inside the facility. Voltage spikes, utility outages, and supply chain failures can trigger shutdowns that no amount of preventive maintenance prevents. A critical spare part unavailable at the wrong moment has the same effect.
What organizations can control is their response. A voltage spike damages a PLC during an electrical storm. With no backup controller on hand and no documented recovery procedure, the line waits for emergency parts and outside expertise. Contingency planning and documented recovery procedures won't prevent the spike — but they significantly shorten the outage.
What Happens When Unplanned Downtime Goes Unaddressed
The direct costs are significant. According to ABB's 2023 survey of 3,215 plant maintenance decision-makers, the median cost for an industrial organization runs $125,000 per hour of unplanned downtime. For large automotive facilities, Siemens puts that figure at $2.3 million per hour. Across the Fortune 500, unplanned downtime costs an estimated $1.4 trillion annually — equal to 11% of revenues.
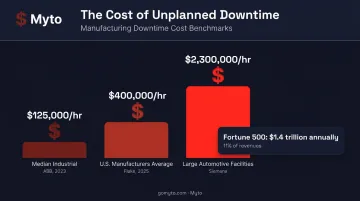
That's the visible damage. The costs that don't show up on a spreadsheet compound quietly over time:
- Customer impact: Inconsistent delivery erodes trust faster than any sales effort can rebuild it
- Team morale: Constant firefighting exhausts maintenance and operations staff; good people leave
- Accelerating degradation: When root causes aren't addressed, the same failure mode repeats — often worse the next time
These consequences don't appear overnight — they build. And they're almost always preceded by warning signs that go unnoticed or unaddressed.
Warning Signs You're About to Experience Unplanned Downtime
These indicators suggest a breakdown is imminent or that systemic vulnerabilities already exist:
- Increasing minor stoppages — Small faults get fixed on the spot without being logged — each one masking a deeper issue that's quietly getting worse.
- Rising MTTR — Breakdowns are taking longer to fix. Siemens reports average recovery time increased from 49 minutes in 2019 to 81 minutes in 2024, suggesting troubleshooting processes aren't keeping pace with equipment complexity.
- Key-person dependency — If one operator's absence creates real downtime risk, that's a knowledge gap one resignation away from becoming a crisis.
How to Prevent Unplanned Downtime
No single measure is sufficient. Effective prevention combines equipment-level practices, people-level practices, and systems-level practices, with each layer compensating for gaps the others can't cover.
Implement Preventive and Predictive Maintenance
What to do:
- Establish a formal preventive maintenance schedule based on manufacturer recommendations — time-based or usage-based inspections, lubrication tasks, and part replacements
- Layer in predictive maintenance using sensor data (vibration, temperature, pressure) to detect anomalies before they reach failure thresholds
- Track all work in a CMMS; prioritize predictive monitoring on high-criticality, high-failure-risk assets first
Why it works: NIST research found that manufacturers relying heavily on reactive maintenance experience 3.3 times more downtime than those in the bottom quartile of reactive-maintenance use. Switching to a proactive posture doesn't just reduce failures — it shifts maintenance teams from emergency response to planned, scheduled interventions.
Adoption gaps remain. ABB's 2023 survey found 21% of industrial businesses still run a run-to-fail strategy, meaning roughly one in five facilities is deliberately absorbing the cost of unplanned failures.
Standardize Procedures and Train Operators
What to do:
- Develop clear, step-by-step SOPs for machine startup, shutdown, changeover, and troubleshooting
- Train all operators on these procedures — not just the most experienced workers
- Cross-train to eliminate single-person dependencies on critical skills
Why it works: Standardized procedures remove the variability that causes human error. Trained operators catch early warning signs and respond correctly the first time, reducing both the frequency and duration of stoppages.
When to update SOPs: After every new process introduction, equipment change, or downtime incident. Waiting for the annual review cycle means living with SOPs that reflect how work used to happen — nearly as risky as having none at all.
Capture and Preserve Frontline Knowledge Before It Disappears
What to do:
- Document the tacit expertise experienced operators use daily: troubleshooting approaches, machine quirks, workarounds, and quality judgments
- Convert that knowledge into structured, accessible documentation any operator can use
- Focus first on the most experienced workers at the highest-risk or most complex lines
Traditional documentation methods miss the most valuable knowledge: how a senior tech actually diagnoses a spindle vibration issue, the specific sequence an experienced operator uses to restart a finicky conveyor, what the outgoing shift lead communicates verbally that never makes it into a handwritten note.
Why it works: When troubleshooting knowledge is captured and surfaced at the moment of fault, recovery is faster. Operators don't need to wait for a specific expert; the knowledge is already in the system.
Platforms like Myto are built for exactly this. Using wearable AI glasses, the platform captures operator expertise hands-free as work happens — no extra steps, no interruption to normal workflow.
When a machine faults, Myto's AI troubleshooting system pulls the relevant equipment history, loads the appropriate SOP, surfaces likely root causes, and walks the operator through a diagnostic checklist with visual aids. The system is trained on plant-specific data — actual SOPs, machine history, ticket logs, and captured expertise — not generic information.
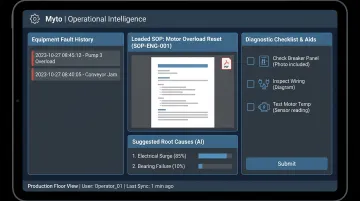
When to start: Start with the most experienced operators on the highest-risk lines, where a single absence creates the greatest downtime exposure.
Monitor Equipment Health with Real-Time Data
What to do:
- Deploy IoT sensors to continuously track equipment performance — availability, OEE, MTBF, MTTR
- Set alert thresholds that notify teams before conditions reach a failure point
- Route alerts directly into team workflows so the right person receives them immediately
Why it works: Continuous monitoring closes the gap between when a fault begins developing and when it's detected. A temperature anomaly caught at +5°C above baseline is a maintenance task. That same anomaly caught after the bearing seizes is a production stoppage.
Rockwell Automation's 2026 State of Smart Manufacturing Report found 59% of manufacturers are actively using smart manufacturing technology at scale — up significantly from recent years. The gap between early adopters and facilities still running on manual checks is widening.
One practical consideration: Rockwell also found that manufacturers are unable to effectively use 57% of the data they collect. Monitoring infrastructure without the intelligence layer to interpret and act on that data delivers only partial value — which is why the practices above, particularly knowledge capture and trained response, matter as much as the sensors themselves.
Tips for Long-Term Prevention and Control
Prevention isn't a project with an end date. These habits build operations that grow more resilient over time:
- Review every downtime event for root causes, not just symptoms. Track trends across months to spot what individual incidents miss.
- **Build a living knowledge base** where every resolved fault gets documented and accessible. Each breakdown should make the next one faster to recover from.
- Cross-train regularly so more team members can cover critical roles. Skill bottlenecks are downtime risks waiting for the wrong moment.
- Use systems that learn from your facility — platforms that integrate machine data, operator behavior, and fault history get better at anticipating risk over time. Myto, for example, gets stronger with each troubleshooting session captured, SOP generated, and shift handoff documented.
Conclusion
Unplanned downtime has identifiable causes — equipment wear, human error, knowledge gaps, and external disruptions — and every one of them can be significantly reduced with the right combination of proactive maintenance, standardized procedures, and knowledge systems.
Manufacturers who treat prevention as an ongoing operational discipline protect their output, their margins, and their workforce from the costly cycle of unplanned stoppages. The facilities that consistently outperform have one thing in common: they've built systems to preserve what they know and act on it faster. Platforms like Myto exist precisely for this — capturing frontline expertise as it happens and turning it into the operational intelligence teams need to keep lines running.
Frequently Asked Questions
What does unplanned downtime mean?
Unplanned downtime is any unscheduled interruption to a machine, system, or production process caused by an unexpected event — equipment failure, human error, or power disruption. Unlike planned downtime, there's no preparation — which is what makes it so costly.
What are the causes of unplanned downtime?
The main causes fall into four categories: equipment wear and deferred maintenance, human error and inconsistent procedures, tribal knowledge gaps where critical expertise isn't documented, and external disruptions like power failures or missing spare parts. Most events involve more than one factor.
What is the difference between planned and unplanned downtime?
Planned downtime is scheduled, communicated in advance, and managed — teams prepare for it and account for it in production schedules. Unplanned downtime is unexpected, typically triggered by failures or emergencies, and almost always more costly and disruptive because there's no preparation.
How do you calculate unplanned downtime?
Add the total duration of all unscheduled stoppages within a given period. To express it as a percentage: (Total Unplanned Downtime ÷ Total Planned Runtime) × 100. This figure is often tracked alongside MTBF and MTTR to identify patterns and improvement opportunities.
What are the 3 P's of maintenance?
The 3 P's are Preventive (scheduled maintenance to stop failures before they happen), Predictive (condition-based monitoring that anticipates failures), and Prescriptive (data-driven guidance on exactly what corrective action to take). Together, they shift maintenance from reactive to proactive.
How much does unplanned downtime cost manufacturers?
Costs vary by industry, but a 2025 Fluke survey puts the average at $400,000 per hour for U.S. manufacturers, while ABB's 2023 industrial survey found a median of $125,000 per hour. Indirect costs — idle labor, emergency parts premiums, and customer impact — frequently exceed the direct repair bill.


